Auto-Recovering From CloudFormation Errors
We’ve noticed some of our users run into a couple of really annoying CloudFormation errors while deploying their services concurrently. We’ve pushed out an update to auto-recover from these errors!
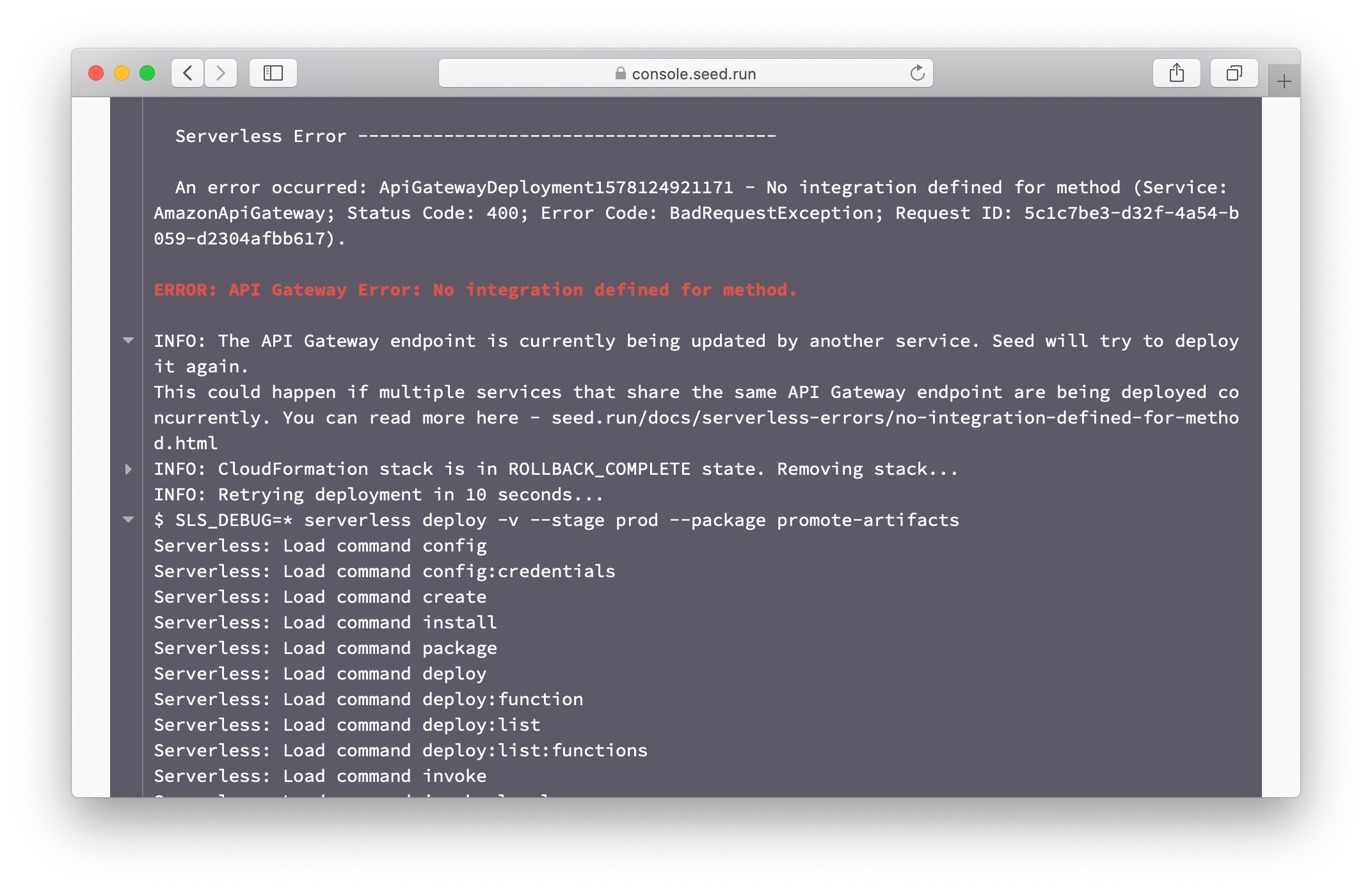
While working on a Serverless Framework app with multiple services that share the same API Gateway project, you might have run across the following errors:
-
No integration defined for method
ApiGatewayDeploymentxxxxxx - No integration defined for method (Service: AmazonApiGateway; Status Code: 400; Error Code: BadRequestException; Request ID: xxxx-xxxx-xxxx-xxxx-xxxx). -
Another Deployment is in progress for rest api with id
An error occurred: ApiGatewayDeploymentxxxxxx - Another Deployment is in progress for rest api with id xxxxxxxx. Please try again later. (Service: AmazonApiGateway; Status Code: 409; Error Code: ConflictException; Request ID: xxxx-xxxx-xxxx-xxxx-xxxx).
These errors happen because Serverless Framework creates an AWS::ApiGateway::Deployment as a part of the CloudFormation stack. And since multiple services are trying to update this for the same API Gateway project, you can run into this error. The first error usually happens when one of the services is creating a new sub-path for the API Gateway project. It’s also very common when an app is being deployed for the first time.
If you run into this error, your app will be stuck in the dreaded ROLLBACK_COMPLETE state. And any subsequent deployments will be met with the following error.
Stack:arn:aws:cloudformation:us-xxxx-x:xxxxxxxxx:stack/xxx-xx-prod/xxxx-xxxx-xxxx-xxxx-xxxx
is in ROLLBACK_COMPLETE state and can not be updated.
To get out of this state, you’ll need to manually go delete the CloudFormation stack from the CloudFormation console. After removing the stack you can try deploying it again. This can be a very painful and time consuming process.
To address this, Seed will automatically detect the above errors, check the CloudFormation stack status, remove the stack, and retry the deployment (up to 3 times) right away. In most cases you won’t even notice the little hiccup!
You can read about the above errors and the auto-recovery process in detail over on our docs.
Update: We’ve added auto-retrying for a couple of other Serverless Framework related errors that you can read about in our docs here.
Do your Serverless deployments take too long? Incremental deploys in Seed can speed it up 100x!
Learn More